Treat LLM Outputs As Candidates, Never As Facts

The fastest way to ship an unreliable AI product is to wire the model directly into your database. I’ve watched teams do it, I’ve done it myself, and the failure mode is always the same. The model returns something plausible. The code calls a save. A week later, support is fielding tickets about duplicate records, contradictory fields, and entities that mysteriously changed their own names.
The model isn’t broken. The architecture is.
Reliability in AI products is not a property of the model. It’s a property of the layer above the model.
Direct-write is brittle by construction
Three things go wrong, and they go wrong every time.
Non-determinism. Run the same prompt against the same input twice. You get two shapes that are 95% identical and 5% different. Different field ordering. A trailing period that wasn’t there before. A confidence score that drifted from 0.82 to 0.79. If the write path treats those as distinct facts, your database now has two opinions about the same thing.
Contradictions across calls. In any non-trivial system you have multiple agents, multiple passes, multiple retries. They will disagree. One says the company has 240 employees, the next says 260, the third says “approximately 250.” If each one writes directly, the last writer wins, and “last” is whatever finished last. That’s not a system. That’s a race.
Cross-batch duplication. You ran extraction yesterday on 5,000 inputs. You run it again today on slightly different inputs with slightly different output. Without a stable identity strategy, you don’t have an updated dataset. You have two datasets layered on top of each other, and the joins downstream are quietly wrong.
None of these are model problems. They’re integration problems.
The candidates-then-reconcile pattern
The pattern is almost embarrassingly simple, which is probably why people skip it.
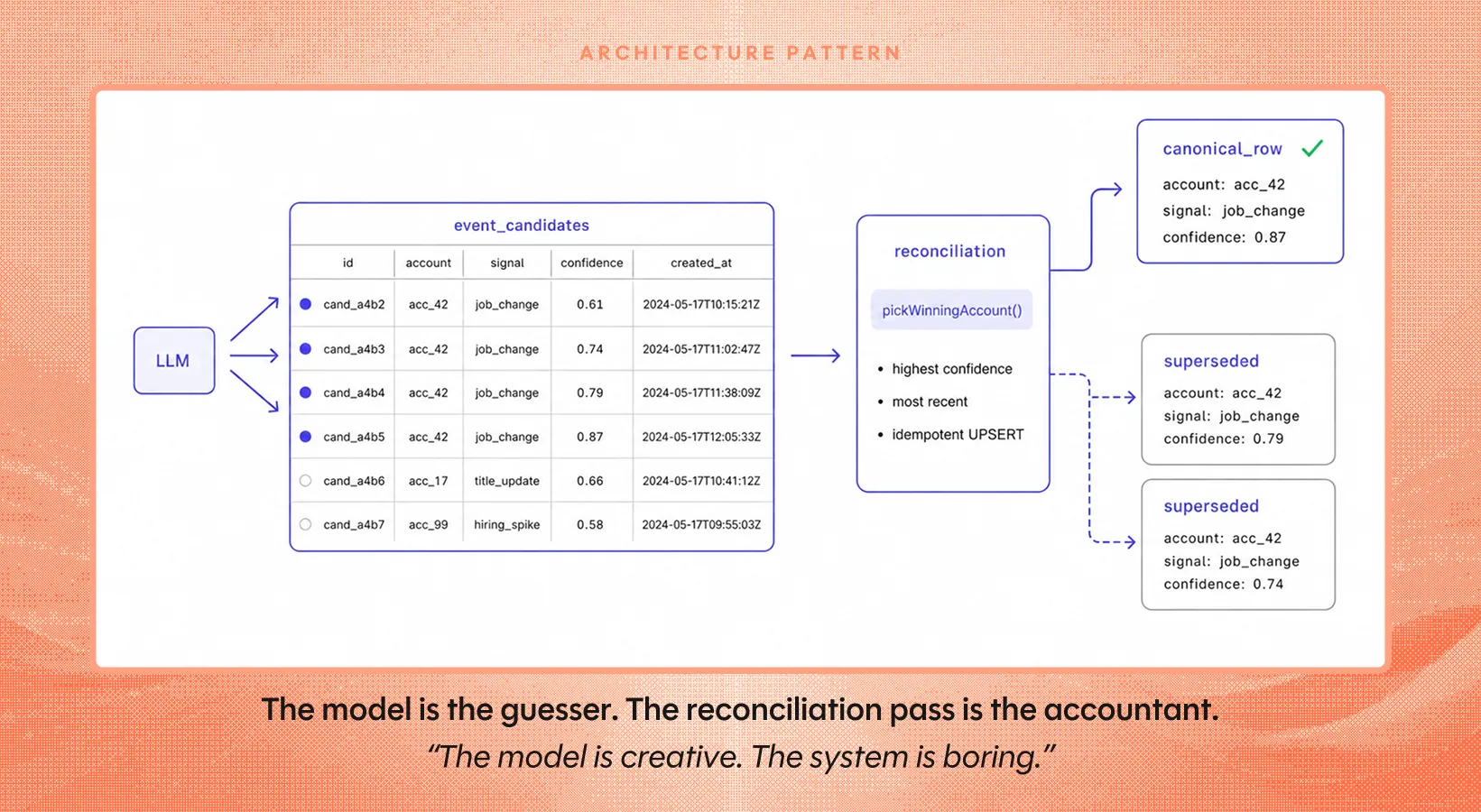
Step one: the model writes to a candidates table. Not the canonical table. A staging area whose only contract is “this is what the model said, with provenance, at this time.”
Step two: a deterministic reconciliation pass reads candidates and produces canonical rows. This pass is plain code. No model in the loop. No prompts. Just rules.
That second step is where the invariants live:
- Stable identity. Decide once how an entity is keyed. Domain. Normalized name. Hash of canonical fields. Then UPSERT on that key, every time, idempotently. Run the pass twice, the database state is unchanged.
- Uniqueness. If your business rule says one row per (tenant, account, signal_type, day), the reconciliation pass enforces it. Not the prompt. Not a hopeful “please return distinct results.”
- Winner-picking on collisions. When two candidates point at the same canonical row with different content, the pass picks a winner using rules you can read out loud. Highest confidence. Most recent. Longest non-null fields. Whatever fits the domain. Crucially, this is testable.
- Provenance. Every canonical row knows which candidate(s) produced it, with timestamps. When something looks wrong, you can walk backwards.
The model is creative. The system is boring. That separation is the entire trick.
Why this works
The model is a good guesser with a wide distribution of outputs. Your database is a strict accountant with hard constraints. You cannot make the guesser into the accountant by prompting harder. You can only put an accountant in between.
Once you do, three nice things happen.
You can re-run the model freely. Replays don’t corrupt state, they produce new candidates. The reconciliation pass converges to the same canonical answer.
You can change the model without changing the schema. Swap providers, upgrade versions, A/B two prompts in parallel. The candidates table absorbs the variance. Canonical state stays clean.
You get a real audit trail. “Why does this account have this signal?” becomes a SQL query, not a forensic exercise.
What this looks like in practice
At Trayo we run LLM agents over a lot of B2B sales signal data. The model writes proposed signal events into an event_candidates table with provenance, and a separate reconciliation pass walks that table to produce canonical rows.
That superseded enum is doing more work than it looks like it’s doing. It’s the reason we can re-run an agent against historical data, see new candidates appear, watch the reconciliation pass demote the old winners, and end up with a canonical view that’s both updated and explainable. Nothing in that loop touches the model.
Every meaningful reliability win in the last year came from that layer, not from the model itself. Better identity keys. Stricter reconciliation rules. More aggressive idempotency. Boring code, doing boring work, on top of creative output.
The honest seam
This pattern has a real cost, and it’s worth naming.
You pay for the candidates table in storage and in mental overhead. Engineers new to the codebase ask, reasonably, why there are two tables for the same concept. The reconciliation pass is its own surface area to test, monitor, and own. When the rules get subtle, debugging shifts from “what did the model say” to “why did the rule pick this candidate,” which is a different muscle.
The pattern also doesn’t help when your identity key itself is wrong. We’ve shipped reconciliation logic that was perfectly correct and perfectly useless because the key it UPSERTed on was too coarse. You find out at the dashboard, not at the table.
The temptation is always to fix flakiness with a smarter prompt. Sometimes that helps at the margins. But if your AI feature feels unreliable in production, the bug is almost never inside the model call. It’s in the seam between the model’s output and your schema.
The reframe
Put a candidates table there. Put a reconciliation pass there. Treat every model response as a proposal, not a verdict.
The good news: that layer is just software. Deterministic, testable, debuggable, the kind of code we already know how to write. We’ve spent decades getting good at it.
So the question worth asking, every time an AI feature feels flaky, isn’t “how do I make the model smarter?” It’s “what would I write if the model wasn’t allowed to touch the database directly?”

